Type | Read/write | Author | Availability |
Read | Finbourne | Provided with LUSID |
The Tools.Pivot provider enables you to write a Luminesce query that pivots data from rows into columns to accomplish the same types of transformations as the SQL Server and Snowflake PIVOT functions.
Note: The LUSID user running the query must have sufficient access control permissions to use this provider. This should automatically be the case if you are the domain owner.
You can use this provider in conjunction with other providers to pivot data, see example 3.
See also: Tools.Unpivot
Basic usage
Input tables
Tools.Pivot takes in one input table and outputs a table of data, see example 1.
Options
Tools.Pivot has options that enable you to refine a query.
An option takes the form --<option>=<value>, for example --key=LusidInstrumentId. Note no spaces are allowed either side of the = operator. If an option takes a boolean value, then specifying that option (for example --matchStringCase) sets it to True; omitting the option specifies False.
The table below provides information on the most commonly used options for Tools.Pivot:
Option | Value | Status | Information |
|
| Optional | The column name that should have its values pivoted into columns. These values must be unique. Defaults to the first non-numeric column. |
|
| Optional | Explicit list of columns to treat as aggregates. Defaults to all numeric columns. |
| String | Optional | How to format key and aggregate columns together if there is more than one aggregate column. Defaults to |
To see a help screen of all available options, their data types, default values, and an explanation for each, run the following query using a suitable tool:
Examples
Example 1: Pivoting basic input data
In this example, we input and aggregate some simple data before pivoting that data.
The table of data returned before versus after pivoting looks like this:

Example 2: Aggregating and pivoting data using particular columns
In this example, we create an input table which looks like this...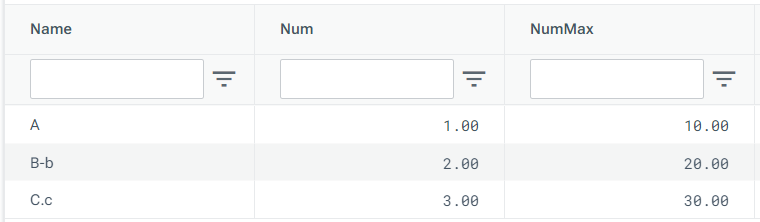
...and pivot the data using the Name column as the key and Num and NumMax as aggregates to produce a column for each Name value.
The table of data returned by the query looks like this:
Example 3: Pivoting a reconciliation response to show metrics in separate columns
You can take a Lusid.Portfolio.Reconciliation.Generic response that looks like this...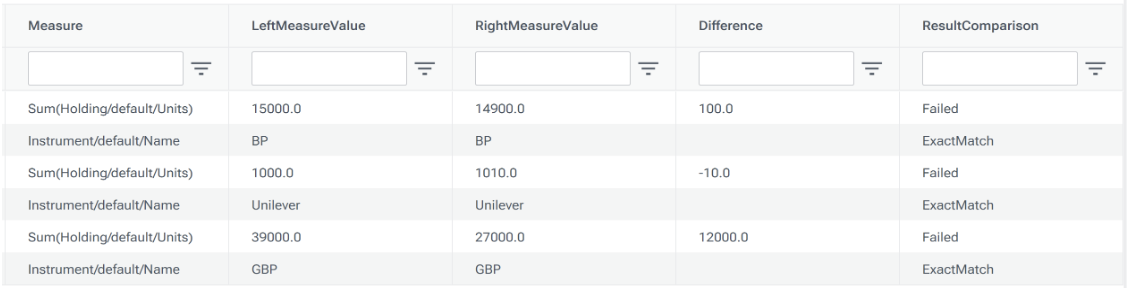
...and run it through the Tools.Pivot provider to return one row per holding instead of one per metric, with each metric shown in duplicated columns rather than in the same columns in different rows.
The table of data returned by the query looks like this, with one row per holding instead of two, and the Instrument/default/Name and Holding/default/Units metrics shown in separate columns: