We recommend that you split your activities between four domains: DEV, SIT, UAT and PROD. Below we provide some best practice recommendations for configuring each domain so you can fully analyze, develop, test and release software safely into production. We also present some common testing workflows In LUSID and explain how you can copy data between domains.
Note: We also recommend that you align your DEV, SIT and UAT domains with the LUSID platform fast ring and your PROD domain with the slow ring. More information about release rings.
Domain configuration
While it is possible to do all your testing in one domain, and segregate production data from testing data using scopes, we recommend separate domains for UAT and testing. In this section we’ll outline the configuration for four domains: DEV, SIT, UAT and PROD.
The DEV and SIT domains
The first two domains are the DEV (development) and SIT (system integration testing) domains:
The DEV domain is used for unit or component CI/CD. This domain is also used for individual developer testing and prototyping. In this domain, your developers can build new tools and prototype against a full set of LUSID APIs in an entirely safe and segregated environment.
The SIT domain is used for integration testing of applications against LUSID. These are integration tests of applications which have a dependency on LUSID data. For example, you might be testing a data loader which loads bonds into LUSID.
Q: Which users should have access to these domains?
Typically, development and service account users only. We would not expect to provide business or end users with access to these domains.
Q: How should we get data into these domains?
We foresee two main channels of data into the DEV and SIT domains:
Create standalone data loaders for each automated test
When writing automated tests against LUSID, you typically want the synthetic test data to be idempotent. In other words, the tests should not have dependencies on data generated outside of the test. For that reason we recommend that you build a process into your tests that generates required data before running the test. See an example in the C# SDK.Take cuts of data from production
You can use the LUSID APIs, SDK or Luminesce to load cuts of production data into the DEV domain. This can be scheduled on a daily/weekly/monthly basis. You can copy over any data that is required: portfolios, holdings, transactions, quotes etc. (See section below on cloning data between domains.)
Q: How should we use scopes in these domains?
There are various ways you can configure scopes, depending on the use case:
Individual developer testing
You might create a scope per user, team or project that provides an entirely separate sandboxed area for testing. For example, you could create roles with access to “jsmith-testing” for an individual user or “new-shk-q4-2021” for a project.Automated unit and integration tests
For unit and integration tests, we recommend that you create testing data in a new scope where each represents a test run (the scope name can be a GUID or unique run ID):In theory, you can also create new data into the same scope during each test. This would refresh or overwrite the previous run’s data in effectiveAt space. The old data would always be available in asAt space.
That said, we recommend using new scopes per run, as each scope also represents a tracking item/log of each run.
Taking cuts from production
As part of the development process, you might want “real looking” data from production against which to write code. For that, you can clone the data from production into designated scopes. For example, you could clone data from the“uk-smallcap-equity” scope in production into the “prod-uk-smallcap-equity” scope in DEV or SIT. You would prefix the scope in dev with “prod” to indicate that the data originated in production. You can also take steps to obfuscate sensitive data.
The UAT domain
The UAT (user acceptance testing) domain is used for testing business workflows that have been developed and tested in the DEV and SIT domains. In this domain, testers and business analysts validate changes before they are promoted into the production domain. With this approach, you can set up automated pipelines that promote changes from DEV/SIT to UAT once they have passed.
Q: Which users should have access to this domain?
This domain is typically for the following users:
Developers and engineers
Service accounts
Business Analysts
Testers
Q: How should we get data into this domain?
The data in this domain will be largely a clone of production. We have two recommendations for copying data into UAT:
Dual-key requests into PROD
With this approach, the data loaders that load data into PROD also create a concurrent request into UAT. This can be configured by maintaining two sets of authentication credentials (one for UAT and one for PROD) that get passed to the same LUSID SDK/data loaders.Use LUSID tooling to copy data between domains
You can use the LUSID APIs, SDK or Luminesce to load cuts of production data into the UAT domain. This could be scheduled on a daily/weekly/monthly basis. You can copy over any data that is required: portfolios, holdings, transactions, quotes, etc. (See section below on cloning data between domains.)
Q: How should we use scopes in this domain?
The data in this domain will mostly be a cut of production data and therefore the scopes will also reflect production.
The PROD domain
The PROD (production) domain is the final domain in the software development process. After the changes have passed through SIT and UAT you will likely want to validate them in production.
Q: Which users should have access to this domain?
This domain is typically used by business and end users only.
Q: How should we use scopes in this domain?
In production, scopes are typically aligned with user groups and business areas. This helps with the management of entitlements. For example, portfolio managers in the Euro Mid Cap Equity team might have portfolios in the “euro-mid-cap-equity” scope and their entitlements and access are configured around this scope. That said, scopes can be used in any scenario where you need to sandbox data into separate namespaces.
Testing LUSID
You can look at testing in LUSID from two perspectives:
Testing your own client specific LUSID configuration
Testing the integration of LUSID with other systems
The first set of tests concern internal LUSID configurations such as recipes or transaction types. For example, you might want to test how changing the quote source in a LUSID recipe impacts the market values in your external valuation reports.
The second concerns how other systems interact with LUSID. For example, you might want to test how adding a new instrument to LUSID impacts your data extractors feeding the same set of valuation reports. In this section, we address both types of testing.
Testing LUSID configuration
LUSID is a sophisticated platform and can be configured in different ways to best meet your requirements. Some of the configuration options have a material impact on how the system behaves. As such, testing your chosen configuration, and managing any changes to it, is a key part of ensuring a successful implementation. Important configuration includes things like:
Transaction types (that control how holdings are generated)
Property and derived property types
Recipes
Security and entitlements configuration
Compliance rules
Q: How should I manage changes to my internal LUSID configuration?
We recommend that you store all this configuration in source control, and manage changes to it using a formal testing and release process.
All LUSID configuration can be managed through our APIs. This makes it easy to integrate your LUSID change management process with any existing DevOps or CI/CD processes. To ensure your chosen LUSID configuration works as intended, we recommend using the DEV and SIT domains to run verification tests. In this environment, you would apply/confirm the configuration changes, and run specific end-to-end tests to confirm the behaviour you expect.
Q: What test cases should I configure?
We recommend using artificial test cases for this purpose (rather than using real production data), as these can be curated to verify the exact behaviour you expect. As noted above, you want these tests to be self-contained. In other words, all the data needed by the test should be setup by the test itself.
The purpose of these tests is to test how your chosen configuration behaves in LUSID. Unless you have a very bespoke workflow or use case, there is less need to test basic LUSID functionality (for example, get holdings from LUSID). FINBOURNE run thousands of standard tests to test LUSID itself every day.
Testing the integration of LUSID with other systems
The other main area of testing centres on the integration with LUSID with other systems in your ecosystem. LUSID will typically be both a consumer and a provider of data to other systems in your estate. The nature of these integrations will depend on the systems in question, but at a high level the testing strategy remains the same.
For scenarios where external systems modify data within LUSID, we recommend that you use your LUSID domains as counterparts to the non-production environments used for development of these other systems.
In dev and test environments, we recommend you establish individual focused test cases to cover the key functions of each integration. By default, we recommend each run of a test sets up all the data required at the start of each run, and cleans up at the end of the test. This ensures the test data is in a known state for the test run, and reduces the possibility of breaks due to data being modified by other processes. As before, unique scopes can be used for each test run to demarcate test data. We recommend using the LUSID DEV and SIT domains for this purpose.
These focused test cases can then be augmented with more comprehensive “prod parallel” scenarios in your UAT LUSID domain. Here, the whole production environment is mirrored as closely as possible, allowing representative tests to be performed, usually using production or production-like data. This may involve the dual-loading of data from upstream production data sources, to ensure realistic data is loaded into your UAT domain.
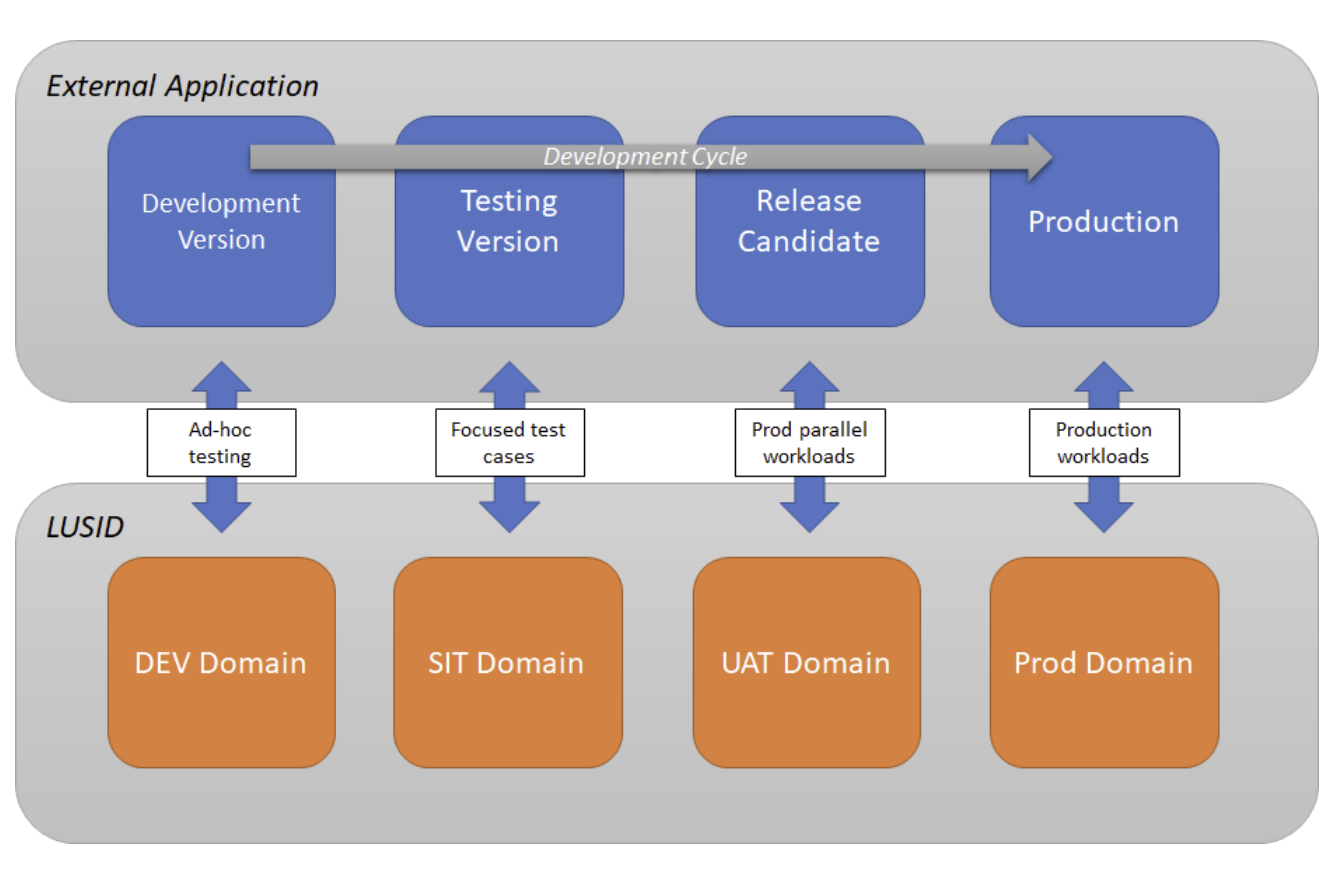
For scenarios where systems are purely consuming data from LUSID, it is possible to direct these applications at your production, or production-parallel (UAT) environment. This allows them to have access to live data, and you can use appropriate entitlements to ensure these systems are not able to modify any data unexpectedly.
LUSID can also support scenarios where systems or users can modify data in the production or UAT domains, but within their own private ‘sandbox’ or ‘validation’ scope. Here, users can alter data in a protected area within the domain, to do testing or other exploratory work, whilst (a) retaining access to production data on which the test may depend and (b) still remaining segregated from any ‘golden source’ production data. Some more detailed examples of these techniques are illustrated in this section.
Copying data between domains
As part of the testing process, you will likely want to clone data from PROD into UAT and DEV. There are various tools in LUSID which can help you achieve this goal. The LUSID APIs were built with “composability” in mind, which means (for example) it is easy to take holdings from one domain (using the GetHoldings API) and upsert them into another domain (using the SetHoldings API).
In future, we may also provide the following tools to help with this process:
A “purge entity” option that will allow you to completely wipe a data entity (portfolio, quote etc.) from LUSID.
A set of Luminesce tools that will enable you to copy one/all portfolios (and all associated data) from one domain. This process could be run ad-hoc or scheduled periodically with a job.
Testing patterns
There are many features in LUSID which can be used to support your testing workflow. In this section we describe some common testing techniques using these features. The workflows below can be used in both production and nonproduction domains. This is a non-exhaustive list.
Validation portfolios
You can use 'validation portfolios' to test the impact of changes in a sandboxed and separate portfolio before pushing these changes to production. For example, imagine you wanted to post a transaction on a new class of bond into a portfolio, to see the impact on your confirmation and settlement systems. To test that change, you could create a portfolio using one of the following approaches:
Clone a live portfolio into a validation scope in PROD using the CreateDerivedPortfolio API
Use a portfolio in UAT which has been copied from PROD
Create an empty transaction portfolio in a new test scope in DEV (if you don’t need “real looking” data)
Note: There is no such thing as a 'validation portfolio' entity in LUSID. Rather, a transaction, derived transaction or reference portfolio could be consider a 'validation portfolio' if it is created in a test scope for the purposes of testing or validation.
You could use the same technique to test:
What-if transactions
Changing the sub-holding key structure on the fund
Back-testing changes to accounting FIFO/LIFO rules
Updating a corporate action source
From an entitlements perspective, all 'validation portfolios' can be entirely segregated from production portfolios. You can implement policies in LUSID so production users never see 'validation portfolios', and testers never see live portfolios in the production scopes.
Scoped instruments
You can scope instruments. This allows you to test changes to core instrument static data without modifying the production instrument. For example, imagine you wanted to change the payment frequency on an OTC to investigate the cash flow impact on your portfolio. You could test that impact by implementing the following workflow:
Clone a live portfolio (with positions on production instruments) into a test scope using the CreateDerivedPortfolio API.
Create the required OTC instrument in the test scope with the payment frequency field modified.
Configure that portfolio to have an override whereby it loads instrument static from the test scope.
Test the impact of the updated instrument on the portfolio’s cash flows.
Delete the test scope instrument after testing.
Transaction type sources
Transaction types control how LUSID generates holdings when you call the GetHoldings or GetValuation API. This is very powerful functionality and it's likely that you’ll want to test before making any changes to transaction type configuration. To do this, you can leverage derived transaction portfolios and the transaction type source field. To illustrate:
Clone a production portfolio into a new test scope (example: “transaction-type-test-20211001”) using the CreateDerivedPortfolio API.
Load a set of transaction types into a test transaction type source (the source on a transaction type provides scope-like behavior).
Generating a holdings report by calling the GetHoldings API.
Test that the holdings have been built as expected from the transactions.
Once completed, delete the portfolio (which also purges the transactions in the portfolio).
Recipes and valuations
By nature, recipes are highly configurable, so it’s likely you will want to test changes to them over time. For example, you might want to test changes to data sources, price hierarchies, instrument risk models, look back periods, pricing fields and so on. To do this, you can clone any recipe into a new scope, make your modifications, and then run an ad-hoc valuation against with the new recipe. You can even use LUSID’s reconcile tool to reconcile a portfolio using the new recipe against the same portfolio using the old recipe.