Type | Read/write | Author | Availability |
Read | Finbourne | Provided with LUSID |
The Tools.Parse.Csv provider enables you to write a Luminesce query that reads CSV, text and more from cells within a table.
Note: The LUSID user running the query must have sufficient access control permissions to use this provider. This should automatically be the case if you are the domain owner.
See also: Tools.Parse.Xml
Basic usage
@data =
select
'<filename>' as Filename,
'<column-name>[, <column-name>...]
<some-data>[, <some-data>...]' as Content;
@parsed =
use Tools.Parse.Csv with @input
--<optional-arguments>
enduse;
select * from @parsed;Input tables
Tools.Parse.Csv takes in one input table and outputs a table of data, see example 1.
Options
Tools.Parse.Csv has options that enable you to refine a query.
An option takes the form --<option>=<value>, for example --fileFilter=myFile.csv. Note no spaces are allowed either side of the = operator. If an option takes a boolean value, then specifying that option (for example --addFileName) sets it to True; omitting the option specifies False.
The table below provides information on the most commonly used options for Tools.Parse.Csv:
Option | Value | Status | Information |
| Regex string, for example | Optional | Based on the |
| Boolean | Optional | Adds a column to the result set containing the file the row came from. |
| String | Optional | Specifies the delimiter that separates values. Defaults to |
To see a help screen of all available options, their data types, default values, and an explanation for each, run the following query using a suitable tool:
@x = use Tools.Parse.Csv
--help
enduse;
select * from @x;Examples
Note: For more example Luminesce queries, visit our GitHub repo.
Example 1: Reading a single CSV
@data =
select
'MyFile.Csv' as Filename,
'TextColumn1, TextColumn2, NumberColumn1, NumberColumn2
some text, more text, 1, 2' as Content
;
@parsed =
use Tools.Parse.Csv with @data
enduse;
select * from @parsed;The table of data returned looks like this:

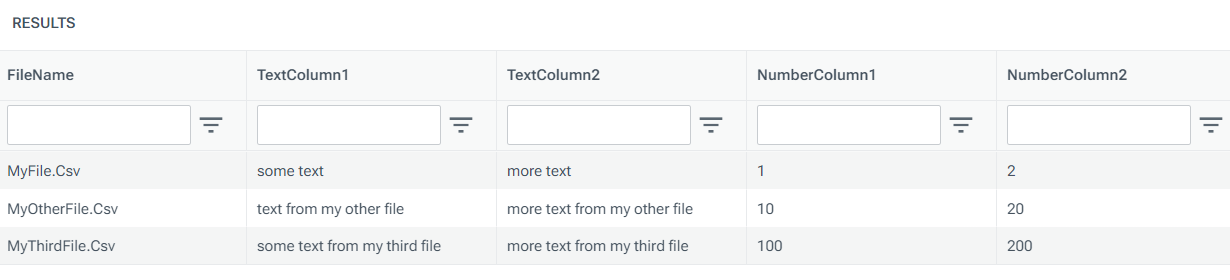
Example 2: Reading multiple CSVs at the same time
In this example, the --addFileName option is specified to ensure the first column in the table of results contains the filename corresponding to each row of data.
@data =
select
'MyFile.Csv' as Filename,
'TextColumn1, TextColumn2, NumberColumn1, NumberColumn2
some text, more text, 1, 2' as Content
union all
select
'MyOtherFile.Csv' as Filename,
'TextColumn1, TextColumn2, NumberColumn1, NumberColumn2
text from my other file, more text from my other file, 10, 20' as Content
union all
select
'MyThirdFile.Csv' as Filename,
'TextColumn1, TextColumn2, NumberColumn1, NumberColumn2
some text from my third file, more text from my third file, 100, 200' as Content
;
@parsed =
use Tools.Parse.Csv with @data
--addFileName
enduse;
select * from @parsed;The table of data returned looks like this:
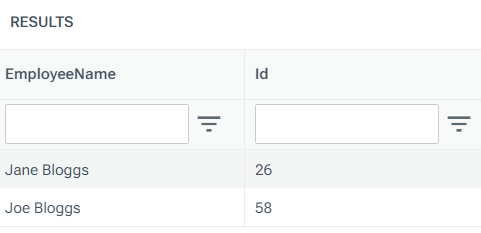
Example 3: Returning only rows with a particular filename
In this example, the --fileFilter option is specified to only select rows with a Filename value that contains ReportFile.
@data =
select
'ReportFile_1.Csv' as Filename,
'EmployeeName, Id
Jane Bloggs, 26' as Content
union all
select
'ReportFile_2.Csv',
'EmployeeName, Id
Joe Bloggs, 58'
union all
select
'UnrelatedFile.Csv' as Filename,
'UnrelatedColumn1, UnrelatedColumn2
some unrelated text, some more text'
;
@parsed =
use Tools.Parse.Csv with @data
--fileFilter=ReportFile.*
enduse;
select * from @parsed;The table of data returned looks like this, with UnrelatedFile.Csv being ignored for not matching the specified --fileFilter value:
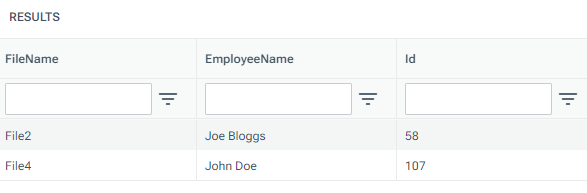
Example 4: Returning only particular rows without any filenames
In this example, the --fileFilter option is specified to only select particular rows to process. As no Filename column is specified in @data, Tools.Parse.Csv gives each row a sequential name which can then be referred to in the --fileFilter option.
@data =
select
'EmployeeName, Id
Jane Bloggs, 26' as Content
union all
select
'EmployeeName, Id
Joe Bloggs, 58'
union all
select
'EmployeeName, Id
Jane Doe, 73'
union all
select
'EmployeeName, Id
John Doe, 107'
;
@parsed =
use Tools.Parse.Csv with @data
--fileFilter=File[2,4]
enduse;
select * from @parsed;The table of data returned looks like this, containing only the second and fourth rows from @data: